hey you guys have already climbed the everest I am just starting. I have one question. How can we transfer data from SQL server to excel file in SSIS. Just give me some info.
ohio,
Go to Data Flow task
Choose Oledb source and configure it and Excel Destination and transfer data. You can use Export/Import Wizard, Linked Server, Opendata source , bcp to do same stuff?
while I am trying to do the character mapping from the data imported from sql its giving me the error message "The last row in the data grid does not contain all necessay fields." What is this issue about?
ohio,
as for ur problem with ssis....transfering SQL Server table data into excel file, u need to do the following tasks:
1) first u need to drag and drop dataflow task in control flow panel and double click the data flow task.
2) double clicking will lead u to dataflow panel, over there drag and drop the source OLEDB for SQL task and configure the connection manager.
3) drag and drop the destination for excel task and link those two tasks.
4) do the column mapping
thats it,
just look around, u will surely be able to do this.
thanks for the instant help. I did it. It takes little bit time to get familar with these tools since there are so many tools there tauko nai khanae.
hey everybody,
can u guys can throw a light on partitioning the table and how it affect the performacne? what are the issues likely to face while implementing partition? if any ideas, please let the knowledge be shared.
Hi
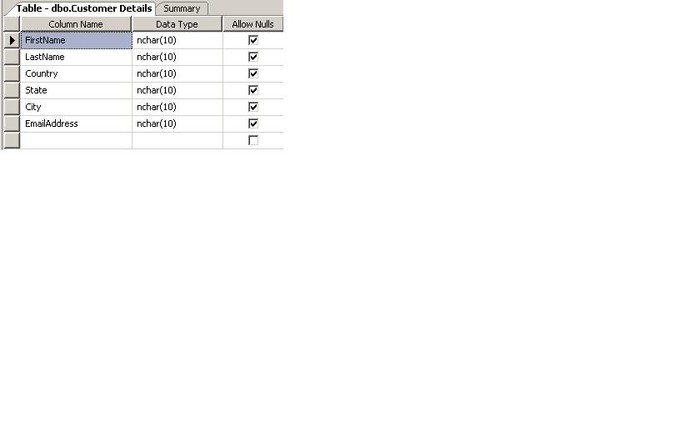
I am doing data transfer from an SQL Server 2005 database to a Microsoft Access Database. I have used Data Reader Source and OLEDB Destination. I made connection with them. When I execute the package it gives me the following error message.
"Warning 1 Validation warning. Data Flow Task: OLE DB Destination [482]: Truncation may occur due to inserting data from data flow column "AddressLine2" with a length of 60 to database column "AddressLine2" with a length of 50"
I have created the access table with the necessary columns before executing the package. My screenshot is here. Do I need to match the data type of the table I have created or while mapping in the OLEDB Destination provider will fix that.
Last edited: 24-Nov-08 03:08 PM

Yes, you must match the datatype and they should have same datalength
thanks for the help virusno1. There is a tool there in oledb connection that will automatically create the query, so we dont have to worry for the datatype.

Partitioning is basically physically arranging data in one single table across multiple physical database files so that only a subset of data is read for most of the queries.
It normally requires a Partition key and partition function. It also requires the use SQL Server Enterprise Edition 2005 or above.
First a little background - if you have huge amount of data - say a billion row or above, it is very expensive to have them in one file. In this case you partition them into multiple physical database files and SQL Server will try to read the data - based on your query - from certain partitions only. This is called partition elimination. Auto increment columns by the way make for very poor partitioned column.
To give a concrete example . Say you have a fact table of sales data for last two years, based on your need you might want to consider it to partition based on every month - so your table will consist of 24 partition. When a new month comes in you simply slide it in and swap out the oldest partition (it is called a sliding Window).
I manage 4 SQL Server enterprise Databases from 3 TB to 13 TB (yes that's Tera byte) with the largest one containing 4.1 billion rows in the biggest fact table with 18 partition for last 18 months (partitioned by a day serial key ). The performance is OK. We are though next year migrating these database either to Vertica, Netezza or TeraData(most probably Vertica if it meets the data load times).
My 13 experience of working with TeraData, Oracle and then SQL Server suggests that you will need partitioned tables only for massive data warehouse applications - and seldom in a OLTP application. Also generally you will see it in traditional big names databases (shared everything database in tech parlance) grafted over the traditional file access mechanism (which hinders parallel data loads by the way) .
If you need to support really huge BI/Data Warehouses with huge dataload and brief windows of loading time - you are better served if you look at something else - for example Vertica, Netezaa or Teradata. You will save yourself a lot of grief. And at that kind of data volume, the price you will pay - work out to be cheaper for Netezaa than for SQL Server (100,000 /TB for Netezaa - hardware/software inclusive - compared to about 50 K for SQL Server EE licences, OS, Server and Storage )
Cheers
Brat.
I am one dba
hehe
how are you jay bro.If you are looking to provide a job, please let me know.
Nishant322,
good bro!!! So another RHCE joins the group!!
gettin' job has never been so difficult!!
HI,
I am looking for SQL developer/DBA training consultancy. Can you guys suggest me any good consulting company that would provide me instructor based training and would also file H1 B for me.
What is the Best efficient tool to migrate 2005 database to Sql server 2008?
Are you asking a trick question or perhaps I misunderstood?
You can either simply run the DVD for SQL Server 2008 and choose the upgrade option.
I personally usually detach the existing production databases before doing the upgrades.
Doing the updates in the cluster can be tricky, I though have always rebuilt the clusters when I update from one version to another. But I guess it is not what you are looking for.
i cann't really run dvd to existing 2005.
I have a few servers in test environment. I need to fresh install 2008 wherer i could migrate 2005 database including logins and all!!
1. Install SQL Server 2008 in a new box.
2. Either backup existing database from 2005 and restore back on on 2008 -it works fine.
3. Either detach existing databases, copy them over to 2008 box and attach them. This also works fine.
4. Use SQL Server data transfer to transfer the database.
5. Generate the script for the existing database, and recreate it on 2008, BCP out the data from old one and pump it back to new one.
So take your pick. Personally I will use either 2 or 3.
Note that once you have upgraded the database to 2008, it cannot be attached or restored back to 2005.
do anybody have knowledge on what are the parameters that get changed during refresin the transaction replication?
Please log in to reply to this post
You can also log in using your Facebook

You might like these other discussions...